Search
8 results.
Use kmap to visualize anonymity/uniqueness in your data
While I was working on a paper recently, I was asking myself the question how to visualize the uniqueness (or anonymity set sizes) in the data. The only visualization that I am still aware of is Fig. 3 in the Panopticlick experiment, which shows anonymity set sizes created by each value of each attribute. This is it:
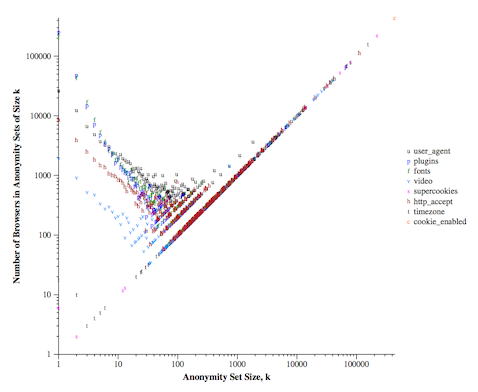
While this is a nice figure, it is quite hard to understand it quantitatively, and it can be even more complicated if you want to compare different datasets by using this visualization method. However, it would be nice to understand the state of uniqueness in datasets, especially if you consider different attributes in each case, apply anonymization or other countermeasures to decrease uniqueness.
This is why I started looking for another option, which finally lead to creating a simple, but heavily customizable plotting function I call kmap [code]. This tool can be used for multiple purposes, either if you are a data scientist experimenting or looking for a way that enables explanatory visualization to non-experts. It is useful to
- visualize how different attributes partitionate your data into anonymity sets,
- how different anonymization schemes or their setup affect uniqueness,
- show how precise a certain fingerprinting method is.
Let's see a nice example based on UCI Adult Data Set. This tabular dataset contains attributes like age, sex or workclass of more than 30k adults. Let's pretend that we are considering releasing this dataset, and we would like to know how many (and which) attributes could be safely released. In order to get a better understanding of this, let's visualize the level of identification (uniqueness) if we release only 3, 6 or 9 attributes of each user. This looks like this with kmap:
| 3 attributes | 6 attributes | 9 attributes |
 |
 |
 |
It is quite easy to tell the differences by looking at the figures: releasing only 3 or 6 attributes is relatively safe (*) as less than 25% of the dataset can be uniquely identified. On the other hand, if 9 attributes are released, that would make almost 75% of users concerned by the release unique.
If you would like to try out kmap for your self, you can find the code and the files for the example in this git repository. Plus, our paper got accepted where this visualization was used, thus more useful examples can be expected.
I would like to hereby thank Gergely Acs, Claude Castelluccia, Amrit Kumar and Luca Melis for their comments while I was developing kmap.
(*) What is safe or not is another question; in some scenarios even having 6% of the users identifiable can be considered as a problem.
Re-addressing fundamental issues of practical privacy technology
Traditional privacy-enhancing technologies were born in a context where users were exposed to pervasive surveillance. The TOR browser could be thought as a nice textbook example: in a world where webizens are monitored and tracked by thousands of trackers (or a.k.a. web bugs), TOR aims to provide absolute anonymity to its users. However, these approaches beared two shortcoming right from the start. First, sometimes it would be acceptable to sacrifice a small piece of our privacy to support or use a service, second, as privacy offers freedom, it could also be abused (think of the 'dark web'). While there have been many proposals to remedy these issues, none in implementations were able to cumulate large user bases. In fact, in recent years privacy research quite rarely reached practical usability or even implementation phase. (Have you ever counted the number of services using differential privacy?)
Due to these reasons, it is nice to see that things are changing. A company called Neura made it to CES this year, who's goal is to provide a finer-grained and strict personal information sharing model, where the control stays in the hand of the users:
[...] firm has created smartphone software that sucks in data from many of the apps a person uses as well as their location data. [...] The screen he showed me displayed a week in the life of Neura employee Andrew - detailing all of his movements and activities via the myriad of devices - phones, tablets and activity trackers - that we all increasingly carry with us. [...] But the firm's ultimate goal is to offer its service to other apps, and act as a single secure channel for all of a user's personal data rather than having it handled by multiple parties, as is currently the case. [...] We are like PayPal for the internet of things. We facilitate transactions, and our currency is your digital identity.
I am a bit sceptic with this privacy selling approach: that much of data could give too much power for that company, and it is not clear what happens if the data is resold (which happens a lot today). It would be a bit more convincing if you could really own the data, and would have cryptograhpic guarantees for that. Until we have that I rather prefer technology where you could buy yout privacy back directly. Returning to the example of web tracking, there are interesting projects (like Google Contributor or Mozilla Subscribe2Web) that would allow to do micro payments to news sites instead of using being tracked and targeted with advertisements.
Another recent development, called PrivaTegrity, addresses accountability of abuses. The project is lead by David Chaum, who is the inventor of the MIX technology that is an underlying concept in digital privacy. While not all details are yet disclosed, it seems Chaum's team are working on a strong online anonymity solution that could be used for a variety of applications, would be fast and resource preserving (so it could work on mobile devices), and would have a controlled backdoor to discourage abusers. I am sure that this latter feature would initiate a large number of disputes, but Chaum claims that revoking anonymity would not remain in the hands of a single government; nine administrators from different countries would be required to reveal the real identity behind a transaction. Let's waint and see how things develop; however, this is definitely a challenging argument for those who vote on erasing privacy.
Here is their paper on the underlying technology.
This post originally appeared in the professional blog of Gábor Gulyás.
Update your TOR Browser settings – otherwise it’s less anonymous than you’d think
In this post we discuss a method that allows tracking users of the TOR Browser Bundle (TBB) with the latest release (5.0.4). We believe that this is an important issue for the TBB users to know, as they would expect anonymity by using TBB, but, as we demonstrate below, this remains a false belief under the default TBB settings.
Although this problem is apparently known by the TOR developers [6], we decided to post our findings due to the following reasons. First, we believe that such a vulnerability should be more clearly communicated to the TOR users. Second, there is a simple workaround that most users can adopt until a patch is delivered by the developers.
Why is TBB anonymity at risk?
TBB is an anonymous browser, thus TBB adopts several measures to make user activities non-trackable, or unlinkable to non-TBB activities. One way for a website to track the activities of a browser is to detect the available fonts on the system. (This is exploited by real-world trackers.) The set of installed fonts is typically highly unique, and it has been shown that it is one of the most unique properties that a browser can have [1]. Even more, fonts can be used to track the OS/device itself [2].
The TOR developer community has already been aware of this problem, and some countermeasures have also been taken: they introduced a limit on the number of fonts a website can load [3]. Due to implementation difficulties, experimental countermeasures have been tested in the alpha release [4], but this seems to be omitted from the current stable version. However, we found that none of these measures work currently, leaving TBB users vulnerable to font-tracking attacks.
Examples: check out if the attack works
It can be easily verified if somebody is vulnerable to the attack or not: we only need to visit a website that obviously loads more than 10 fonts, and if it is successful, we have a problem. For example, you can visit this site [7] and check how many fonts it can load. Alternatively, cross-browser fingerprinting sites [5] can be used to test this attack more systematically.
In the following two screenshots, we compared the detected fonts on Linux and on OSX using TBB (left), and also using a regular browser (right). As you can see, more-or-less the same fonts are detected, which shows that TBB can be tracked across multiple sites, and activities within TOR can potentially be linked with activities outside of TOR.


In the following screenshot we show that the list of installed fonts can also be inferred regardless of the privacy settings in TBB. The highest setting, which provides the strongest privacy protections in TBB, seemingly prevents tracking as it disables JavaScript on all sites. However, this is not perfectly the case: arbitrary fonts can be still loaded by CSS.
The CSS font leakage can be checked in our demonstration here [7].

How should I update TBB settings?
Fortunately there are two things that we can do about this. The better solution is to disable the browser to load any fonts except four of them. This can be done by opening the advanced font settings window (Settings > Content > Advanced) and unselecting the option that “websites could choose fonts on their own”. This will provide sufficient protection with all of the four privacy levels that TBB offers. The other possibility is to use the highest privacy setting offered by TBB, but that will further degrade user-experience, and as discussed above, it is not bullet-proof.
This setting could help with preserving anonymity while waiting for the new stable release to deliver a working solution. (That would desirably also cover the vulnerability against another type of fingerprinting [8].)
Gábor Gulyás, Gergely Ács, Claude Castelluccia
EDITED (2015-12-01): Typekit example removed (our example is enough now).
Footnotes and links
[1] In the Panopticlick experiment fonts alone measured a 13.9 bit entropy over 286,777 users. After plugins, it was the second most unique property of browers. The paper is available here: https://panopticlick.eff.org/browser-uniqueness.pdf
[2] Fonts could be extracted in a way that allows cross-browser fingerprinting. Paper: http://gulyas.info/upload/GulyasG_NORDSEC11.pdf
[3] If you are using TBB, and open about:config, you’ll find two TBB specific settings on this called as browser.display.max_font_count and browser.display.max_font_attempts.
[4] Check here: https://blog.torproject.org/blog/tor-browser-50a4-released
[5] http://fingerprint.pet-portal.eu
[6] A workaround was suggested here: https://trac.torproject.org/projects/tor/ticket/5798#comment:13
[7] CSS-based font tester: http://webpoloska.hu/test_font.php
[8] Further information can be found in the related ticket and article on the subject.
https://trac.torproject.org/projects/tor/ticket/13400
Predicting anonymity with neural networks
In a previous blog entry, I described how random forests could be used to predict the level of empirical identifiability. I have also been experimenting with neural networks, and how this approach could be used to solve the problem. As there is a miriad of great tutorials and ebooks on the topic, I'll just continue the previous post. Here, instead of using the scikit-learn package, I used the keras package for modeling artificial neural networks, which relies on theano. (Theano allows efficient execution by using GPU. Currently only NVIDIA CUDA is supported.)
The current setting is the same described in the previous post: node neighborhood-degree fingerprints are used to predict how likely it is that they would be re-identified by the state-of-the-art attack. As I've seen examples using raw image data for character classification (as for the MNIST dataset) with a Multi-Layer Perceptron structure, I decided to use a simple, fully connected MLP network, where the whole node-fingerprint is fed to the net. Thus the network is constructed of an input layer 251 neurons (with rectified linear unit activation, or relu in short), a hidden layer of 128 neurons (with relu). To achieve classification, I used 21 output neurons to cover all possible score cases in range of -10, ..., 10. Here, I used a softmax layer, as an output like a distribution is easier to handle for classification. See the image below for a visual recap.

I did all the traning and testing as last time: the perturbed Slashdot networks were used for training, and perturbations of the Epinions network were serving as test data. In each round with a different level of perturbation (i.e., different level of anonymization or strength of attacker background knowledge) I retrained the network with Stochastic Gradient Descent (SGD), using the dropout technique – you can find more of the details in the python code. As the figure shows below, this simple construction (hint: and also the first successful try) could beat previous results, however, with some constraints.

In the high recall region this simple MLP-based prediction approach proved to be better than all previous ones. While for the simulation of weak attackers (i.e., small recall, where perturbation overlaps are small), random forests obviously are the best choice. You can grab the new code here (you will also need the datasets from here).
This post originally appeared in the professional blog of Gábor Gulyás.
Predicting anonymity with machine learning in social networks
Measuring the level of anonymity is not an easy task. It can be easier in some exceptional cases, but that is not true in general. For example in an anonymized database, we could measure the level of anonymity with the anonymity set sizes: how many user records share the same properties, which could make them identifiable. (And here is the point where differential privacy fans raise their voices, but that story is worth another post.) However, this is much harder if we think about highly dimensional datasets where you have hundreds of attributes for a single user (think of movie ratings, for example).
New doctoral dissertation on anonymity
Gábor György Gulyás, founding Editor-in-Chief of the International PET Portal and Blog successfully defended his PhD thesis titled "Protecting Privacy Against Structural De-Anonymization Attacks in Social Networks" earlier today. The peculiarity of the public defense held at the Faculty of Electrical Engineering and Informatics, Budapest University of Technology and Economics, was that not only the dissertation had been written in English but the defense procedure has also been conducted in English, and one of the two opponents, Julien Freudiger participated in the event from the US through Skype connection. The doctoral committee accepted the thesis and the oral presentation with the highest grade and awarded the PhD degree to the doctoral candidate.
A study publishing the results of the doctoral research can be accessed here.
UPDATE (2015-05-15): the dissertation is available online here.
Need of anonimity II. – Rock privacy in 8 easy steps!
In our previous post on the importance of privacy we highlighted why we believe that it matters, how has our view changed on the issue in the past few decades. In this post we would like to share some more insights, who could be potential threat to your privacy,
Intruders of online privacy – who are they and what do they do?
One of the main problems is that no one have a clue who is conducting surveillance (in more professional terms: there is a lack of the proper attacker model) and what are their reasons of collecting information. However there are a few outstanding, widely known issues, government surveillance is surely such a thing, especially since the PRISM-case.
Many governments – similar to the one in question – sacrifice (a lot of) privacy in exchange of (some) security; for instance, the Data Retention Directive in the EU regulates what information telecommunication companies need to retain in order to help governing forces combating terrorism. Although it is put into practice by most member states, we know little about exact implementations of the directive over fulfillment of surveillance obligations exact technical details at involved telecommunication parties seem to be white spots of the process.
While this type of mass-surveillance has less effect on individuals (except for the ones under targeted observation), it is problematic because it can be executed secretly leading to potential abuses (like it happened in the US), and the secrecy around the implementation can loosen democratic control over these operations (as in the EU).
Meanwhile, surveillance committed for commercial purposes have a rather significant impact at a personal level. This kind of activity includes various actors, ranging from large service/platform providers selling out the data of their users (are you on Facebook?), to marketers using personal profiles to steer their business decisions. For example if you have ever surfed on the net for the best priced plane tickets and watch them going up and down – you may be familiar with behavioral advertising and dynamic pricing. Although there are clearly some legal applications for such uses of profiles (especially if they were collected and used with consent), most are not beneficial for the data subjects.
Thus, these companies get the chance of undetectably influence our choices. Like in the case of Orbitz offering Mac users more expensive hotels, or when it turned out that how ‘bad’ friendships (on social networks) can affect the credit score of someone. Besides, it is also wise to think about others who can access our data and use it occasionally, e.g., as auxiliary data during a job interview.
A lost battle vs. reasons to act for your privacy
At the time of writing, owing to the continuously emerging revelations of the Snowden case we know more and more details of NSA surveillance affecting most people throughout the globe. However, there is probably a lot more to come and it is also likely that the security industry will significantly change soon – so keep that in mind while going on with reading.
Until the fall of 2013 we learn that despite the number of experts NSA employees or the extent of hardware it has, the agency rather seeks cooperation with companies and service providers all over the world to build its own backdoors into software and services. At the same time the NSA possibly influenced the creation of standards and protocols, and enactment of a law was also planned in order to have access to arbitrary other companies (though it was pushed by the FBI).
Fortunately, according to the revealed documents, following a few simple guidelines can make mass surveillance harder, and can help us to be safer online. We still have strong cryptography to rely on, and using open source software is also crucial to succeed. Regularly overviewed open source software is less likely to have embedded backdoors, and if we use standardized protocols, other parties have less chance to influence parameters and stuff (or use software that would do so).
Reinforcing against commercial parties should be done accordingly: while it is difficult to avoid all kinds of surveillance, we can make the duty of the watchers so hard and expensive that we can pass under the radar for most of them. As these companies have several limits regarding founding, technological expertise, etc., usually fighting against a small resisting group simply isn’t worth it. In addition, going for wholesale surveillance is not always a valid business goal for many.
So this is not yet over – take the first steps!
Privacy is not just about revealing secrets – it is far more complex than being a form of secrecy. Your privacy can also be invaded even if no secrets are revealed, implicating that privacy is very sensitive to technological innovations and changes. For instance, someone having a public micro blog on a specific topic (e.g., French cuisine or sports) may not reveal information about the personal life of the author. Meanwhile, timing of the messages and location information attached to tweets can be used to correlate daily routine and other habits. Thus we should be alert of the privacy implications of new technology while it continues reshaping our everyday life.
Download the ebook on strengthening privacy!
This post originally appeared in the Tresorit Blog.
Need of anonimity I. – How to rock privacy
The recent decades speeded up, twisted and completely changed the world. Modern technology not only reshaped the societies we live in, but it also undetectably pervaded our everyday life to change our ways of thinking.
If you are an average smartphone user you probably downloaded around 10 to 100 app in the past few weeks, to track your workout performance, record your spending, manage photos, follow the most important happenings in your network, kill time with the latest (and coolest) game and so on. This is just a single device of those you are using. Significant information we give out on where we are, what we do and what we probably think are accessible today for many parties, and in addition, we often voluntarily provide supplement to data being collected
This process could be described from many aspects. However, the overview of web tracking techniques makes an outstanding example on how the profiling based market extended tremendously over the years (e.g., behavioral profiling), and how conscious webizens engaged trackers in a seemingly never ending circulation: finding the way to avoid tracking and discovering new tracking mechanisms.
While general concern for online privacy was continuously growing, recently leaked NSA documentation revealing world-wide wholesale surveillance gave a boost to the rise of awareness. Despite the fact that we arrived to a positive landmark, there are still several white spots on the map of privacy and yet many false-beliefs surrounding the topic.
I have nothing to hide – why should I care?
There are several typical phrases denying the need for privacy that often emerges from the media. Probably the most frequently used one states that “if you have nothing to hide, you should be not worried” (and similar ones with different wordings). Eric Schmidt is also famous for quoting this, while now he yet seems to be seeking privacy himself.
First of all: is privacy about hiding something? Definitely not. Bruce Schneier gives a few good counterexamples such as the need to “seek out private places for reflection or conversation”, “sing in the privacy of the shower”. We could think of sharing moments with the ones we love, or seeking loneliness to find ourselves. There are several other private moments in everyday life to choose from.
Privacy is also important as a basis for the freedom of speech. Dictatorships in the twentieth century showed us that if privacy is omitted (e.g., by allowing targeted surveillance on people disagreeing with the system), this will react in changing individual behavior and public speech. By looking it this way, we can see how privacy means freedom, why it is a basic human need.
Beside some level of secrecy, privacy is also includes control for disclosure among several other things (e.g., “my house my castle”). Daniel Solove quotes pretty good replies from his readers to the misunderstanding in question:
- My response is “So do you have curtains?” or “Can I see your credit-card bills for the last year?”
- So my response to the “If you have nothing to hide … ” argument is simply, “I don’t need to justify my position. You need to justify yours. Come back with a warrant.”
- I don’t have anything to hide. But I don’t have anything I feel like showing you, either.
- If you have nothing to hide, then you don’t have a life.
- It’s not about having anything to hide, it’s about things not being anyone else’s business.
Another problem that such an attitude can justify uncontrolled surveillance. If information is collected without a defined purpose, it can be easily abused. Definition of what is good or wrong can change over time, and what was once collected can be even used to condemn data subjects if it is in the interests of the currently governing forces. This implies several other questions. What data would be stored on you and for how long? Who could access it and make copies of it?
In addition, mistakes can happen anytime. For example, your financial records can look misleadingly suspicious, sufficiently convincing for the tax office to investigate you. Or your data can be leaked accidentally or hacked. In this case, how could you tell what is out there in the public? What is once out there, it stays there.
There are other public voices stating that we don’t care about privacy anymore or don’t simply need it in the digitalized age we live in. However, research shows that even new generations do care about privacy, though for them privacy is more about control. This might be unexpected regarding the strong influence of new technology on their lives, and propaganda of technology companies trying to have the young generation more engaged with their products (not surprisingly: most of their business models rely on controlling vast amount of user-related data).
We got a little enthusiast on the topic, so by end of the process we found a [tltr] alert flashing over the post. This is why we break this down to two pieces. The second will follow in some days. We reward your patience, by adding a super useful e-book on privacy, with many tips and tricks. Stay tuned, it is going to be great!
This post originally appeared on the Tresorit Blog.